Data Structures Compendium
Data structures are the building blocks of efficient software. You do not need to know every one, but a solid grasp of the fundamentals and when to reach for each will take you a long way. This page serves as both an index and a learning roadmap for the data structures and related topics I have written about.
The diagram below shows how the structures relate to each other. Dashed arrows indicate “implements” or “builds on” relationships.
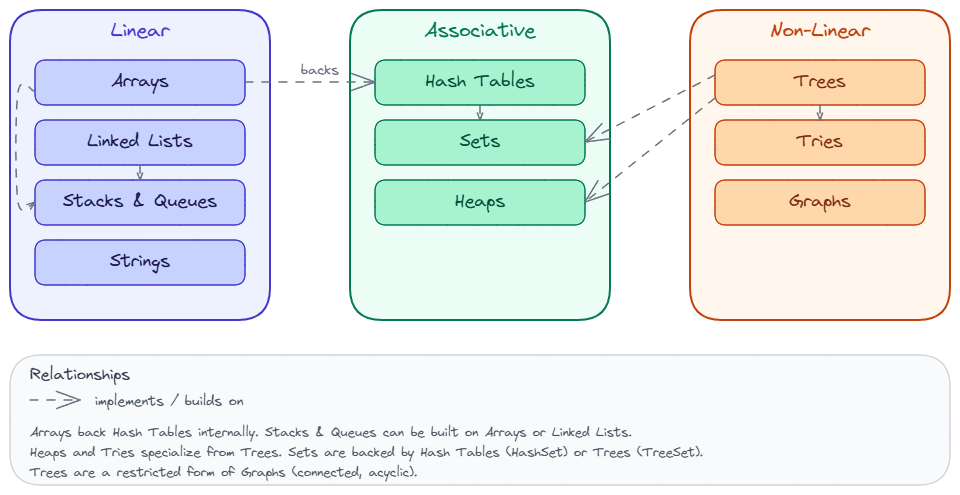
Suggested Learning Path
If you are starting from scratch, I recommend reading them in roughly this order: foundational concepts first (complexity analysis, memory, Big O), then linear structures (arrays, linked lists, stacks and queues), then associative structures (hash tables, strings), and finally non-linear structures (trees, graphs). The foundations section gives you the vocabulary and mental models you need to reason about everything that follows.
Foundations
These posts cover the conceptual tools you need before working with any specific data structure. Understanding how to measure performance and how memory works will make every topic below click faster.
- Complexity Analysis – how to measure and compare algorithm efficiency using time and space complexity. Start here if you want a framework for evaluating any data structure or algorithm.
- Memory – how data is stored and accessed in RAM, including the distinction between stack and heap memory. Essential for understanding why certain structures are faster than others.
- Big O Notation – the standard notation for describing the upper bound of an algorithm’s growth rate. Once you internalize this, you can quickly compare trade-offs between different approaches.
- Logarithm – the mathematical concept behind the efficiency of divide-and-conquer algorithms and balanced trees. Worth understanding because O(log n) shows up everywhere in computer science.
Linear Structures
Linear structures store elements in a sequential order. They differ in how they allocate memory and which operations they make cheap.
- Arrays – contiguous blocks of memory offering O(1) access by index. The most fundamental data structure and the default choice when you need fast random access to elements.
- Linked Lists – sequences of nodes where each node points to the next, enabling O(1) insertions and deletions at known positions. Reach for these when your workload is dominated by frequent insertions or removals rather than lookups.
- Stacks and Queues – LIFO and FIFO structures used extensively in algorithms, parsing, and scheduling. Stacks are the go-to for undo functionality and expression evaluation; queues show up in BFS, task scheduling, and buffering.
- Strings – sequences of characters with their own set of manipulation techniques and pattern-matching algorithms. Practically every application deals with strings, and understanding their immutability and encoding matters more than most people expect.
Associative Structures
Associative structures organize data for fast retrieval based on keys or priority rather than position.
- Hash Tables – key-value stores providing average O(1) lookup through hashing functions. The workhorse behind dictionaries, caches, and deduplication. If you need fast lookups by key, this is almost always the answer.
- Heaps – specialized tree-based structures that satisfy the heap property (min-heap or max-heap). They provide O(1) access to the minimum or maximum element and O(log n) insertions and deletions, making them the backbone of priority queues, heap sort, and shortest-path algorithms like Dijkstra’s.
Non-Linear Structures
Non-linear structures model hierarchical and networked relationships. They are essential for representing anything from file systems to social networks.
- Trees – hierarchical structures with a root node and children, fundamental to searching, sorting, and representing nested data. Binary search trees give you O(log n) lookups, and balanced variants like AVL and red-black trees guarantee that performance.
- Graphs – collections of vertices and edges that model relationships and networks. Whenever your problem involves connections between entities (routes, dependencies, friendships), graphs are the right abstraction.
Algorithms
- Depth First Search in Java – a tree and graph traversal algorithm that explores as deep as possible along each branch before backtracking. One of the first traversal algorithms you should learn because it forms the basis for solving problems like cycle detection, topological sorting, and pathfinding.
Additional Structures Worth Knowing
These are more specialized, but they come up often enough that you should at least know what they are and when to consider them.
- Tries (Prefix Trees) – tree-like structures optimized for storing and searching strings by their prefixes. Tries excel at problems involving autocomplete, spell-checking, and IP routing, offering O(m) lookup time where m is the length of the key.
- Sets – collections that store unique elements with no duplicates. In Java,
HashSetgives you O(1) average-case add, remove, and contains operations, whileTreeSetkeeps elements sorted and offers O(log n) for the same operations. Reach for a set whenever you need to enforce uniqueness or perform membership checks efficiently.
Related posts: Complexity Analysis, Big O Notation